






芯片资讯
- 发布日期:2024-01-05 12:45 点击次数:159
Source: DYLAN PATEL,MYRON XIE, GERALD WONG, AI Capacity Constraints - CoWoS and HBM Supply Chain, July 6, 2023
生成式人工智能已经到来,它将改变世界。自从ChatGPT风靡全球,让我们对人工智能的可能性充满想象力以来,我们看到各种各样的公司都在争相训练AI模型,并将生成式人工智能应用于内部工作流程或面向客户的应用程序中。不仅是大型科技公司和初创公司,很多非科技行业的财富5000强公司也在努力寻找如何部署基于LLM的解决方案。
当然,这将需要大量的GPU计算资源。GPU销售量像火箭一样飙升,供应链难以满足对GPU的需求。公司们正在争相购买GPU或云实例。
即使是OpenAI也无法获得足够的GPU,这严重制约了其近期的路线图。由于GPU短缺,OpenAI无法部署其多模态模型。由于GPU短缺,OpenAI无法部署更长的序列长度模型(8k vs 32k)。
与此同时,中国公司不仅在投资部署自己的LLM,还在美国出口管制进一步加强之前进行库存储备。例如,抖音背后的中国公司字节跳动据说正在向Nvidia订购价值超过10亿美元的A800/H800。
虽然有许多合理的用例需要数十万个GPU用于人工智能,但也有很多情况是人们急于购买GPU,试图构建他们不确定是否有合法市场的项目。在某些情况下,大型科技公司正在努力迎头赶上OpenAI和Google,以免被抛在后头。大量风投资金涌入那些没有明确商业用例的初创公司。我们了解到有十几个企业正在尝试在自己的数据上训练自己的LLM。最后,这也适用于包括沙特阿拉伯和阿联酋在内的国家,他们今年也试图购买价值数亿美元的GPU。
即使Nvidia试图大幅增加产量,最高端的Nvidia GPU H100也将在明年第一季度之前售罄。Nvidia将逐渐提高每季度H100 GPU的发货量,达到40万枚。
今天我们将详细介绍Nvidia及其竞争对手在生产方面的瓶颈以及下游容量的扩展情况。我们还将分享我们对Nvidia、Broadcom、Google、AMD、AMD Embedded(Xilinx)、Amazon、Marvell、Microsoft、Alchip、Alibaba T-Head、ZTE Sanechips、三星、Micron和SK Hynix等公司每个季度供应增长的估计。

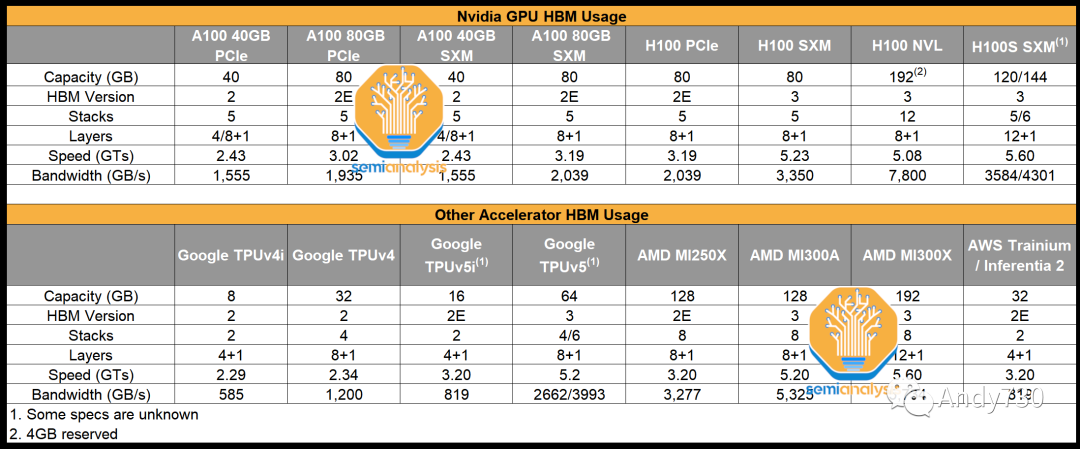
Nvidia的H100采用CoWoS-S封装,共有7个芯片组件。中心是H100 GPU ASIC,其芯片尺寸为814平方毫米。周围是6个HBM存储堆叠。HBM的配置因不同的SKU而异,但H100 SXM版本使用HBM3,每个堆叠为16GB,总内存容量为80GB。H100 NVL将有两个封装,每个封装上有6个活动的HBM堆叠。
在只有5个活动HBM的情况下,非HBM芯片可以是虚拟硅,用于为芯片提供结构支撑。这些芯片位于硅中间层之上,该硅中间层在图片中不清晰可见。这个硅中间层位于ABF封装基板上。
01.GPU芯片和TSMC制造
Nvidia GPU的主要计算组件是处理器芯片本身,采用定制的TSMC工艺节点“4N”制造。它在台湾台南的TSMC Fab 18工厂中制造,与TSMC N5和N4工艺节点共享设施。这不是生产的限制因素。
由于个人电脑、智能手机和非人工智能相关的数据中心芯片市场的严重疲软,TSMC的N5工艺节点利用率降至70%以下。Nvidia在获取额外晶圆供应方面没有遇到问题。
事实上,Nvidia已经订购了大量用于H100 GPU和NVSwitch的晶圆,并在这些芯片需要出货之前立即开始生产。这些晶圆将在TSMC的晶圆库中存放,直到下游供应链有足够的能力将这些晶圆封装成成品芯片。
基本上,Nvidia正在利用TSMC低利用率的情况,并在后续购买成品的路上获得一些价格优势。
芯片库,也被称为晶圆库,是半导体行业的一种做法,即将部分加工或已完成的晶圆存放,直到客户需要时再提供。与其它一些晶圆代工厂不同,TSMC会帮助客户将这些晶圆保留在自己的账面上,几乎进行完整的加工。这种做法可以使TSMC及其客户保持财务灵活性。由于这些晶圆只是部分加工,所以存放在晶圆库中的晶圆并不被视为成品,而是被归类为在制品(WIP)。只有当这些晶圆完全完成时,TSMC才能确认收入并将这些晶圆的所有权转移给客户。
帮助客户调整资产负债表,使其看起来库存水平得到了控制。对于TSMC而言,好处在于可以提高利用率,从而支持利润率。然后,当客户需要更多库存时,这些晶圆可以通过几个最后的加工步骤完全完成,然后以正常销售价格甚至略有折扣交付给客户。
02.数据中心中HBM的出现
AMD的创新如何帮助了Nvidia
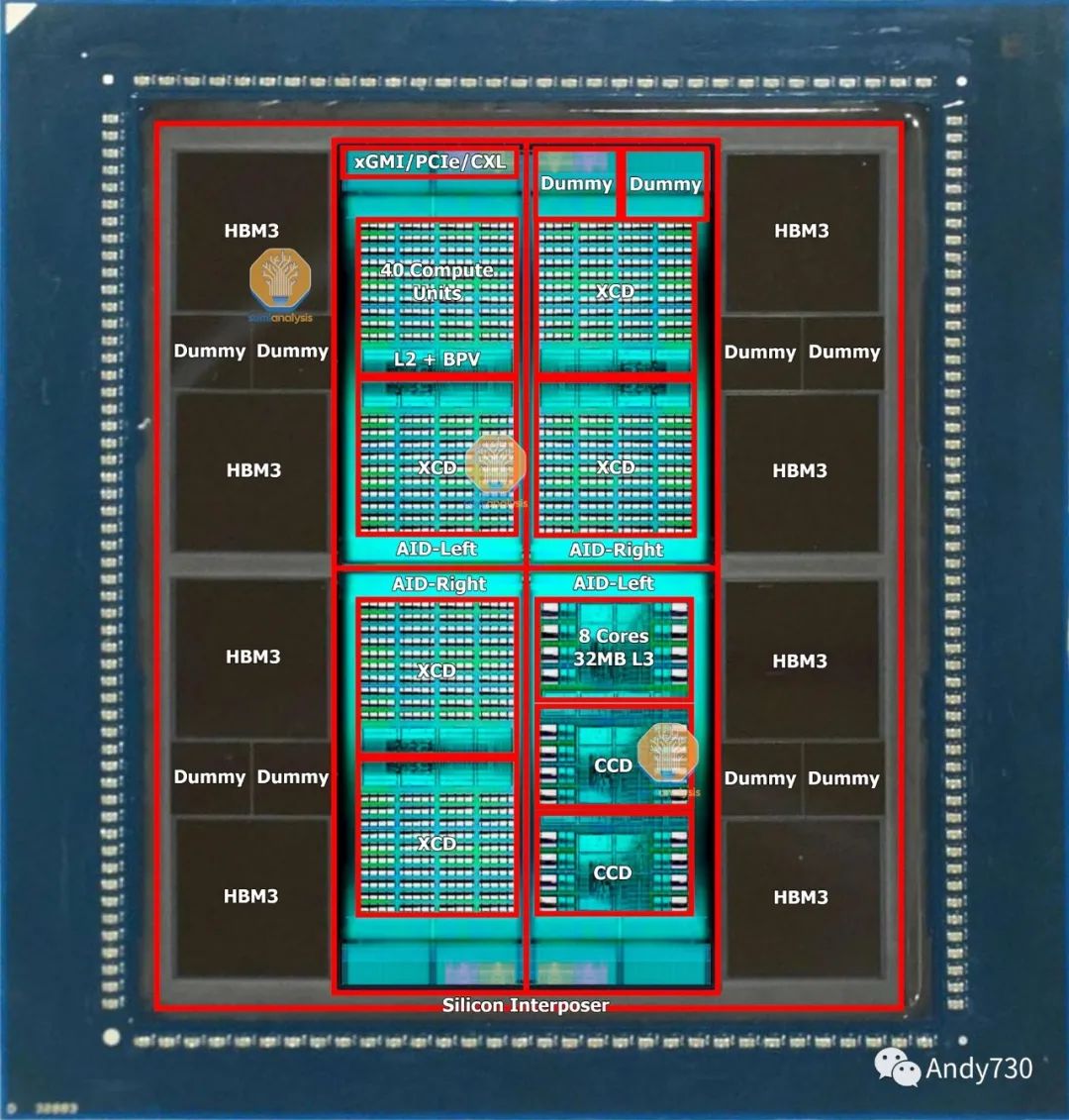
围绕GPU的高带宽内存(HBM,High Bandwidth Memory)是下一个重要组件。HBM供应也有限,但正在增加。HBM是通过硅穿透孔(TSV,Through Silicon Vias)连接的垂直堆叠DRAM芯片,并使用TCB(thermocompression bonding,在未来需要更高堆叠层数时将需要使用混合键合技术)进行键合。在DRAM芯片的下方是一个作为控制器的基础逻辑芯片。通常,现代HBM有8层存储芯片和1个基础逻辑芯片,但我们很快将看到具有12+1层HBM的产品,例如AMD的MI300X和Nvidia即将推出的H100升级版。
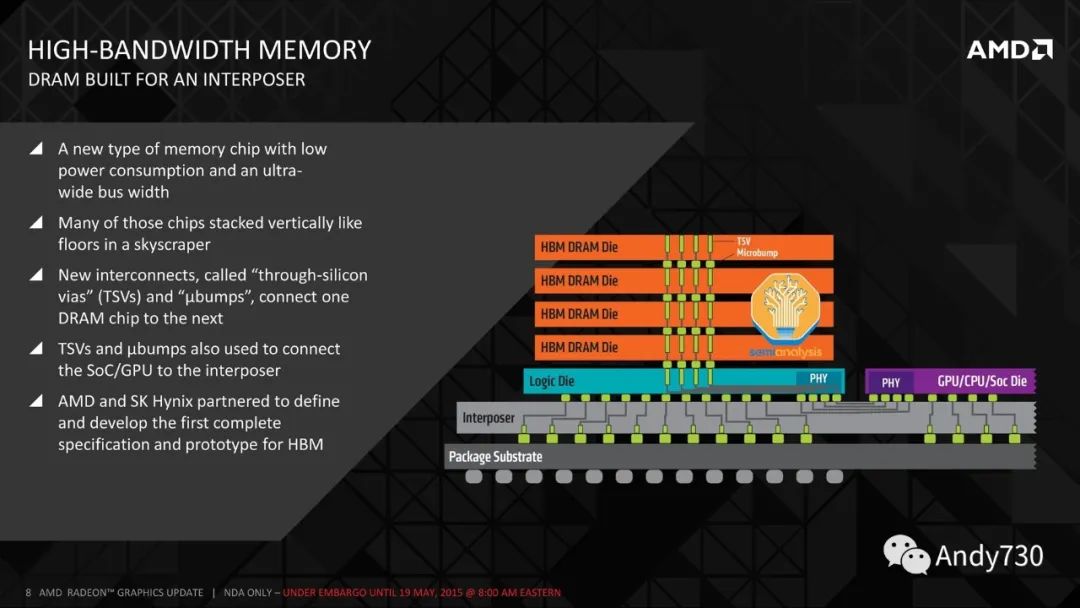
有趣的是,尽管Nvidia和Google是HBM的最大用户,但是AMD是HBM的先驱。在2008年,AMD预测,为了匹配游戏GPU性能的持续提升,需要更多的功率,这将需要从GPU逻辑中分流,从而降低GPU性能。AMD与SK Hynix和其它供应链中的公司(如Amkor)合作,寻找一种能够在更低功耗下提供高带宽的存储解决方案。这导致了2013年由SK Hynix开发的HBM技术的诞生。

SK Hynix于2015年首次为AMD的Fiji系列游戏GPU提供了HBM技术,这些芯片由Amkor进行了2.5D封装。随后,在2017年推出了Vega系列,该系列采用了HBM2技术。然而,HBM对游戏GPU性能并没有带来太大改变。由于性能上没有明显的优势,再加上成本较高,AMD在Vega之后又转而使用了GDDR技术来供应其游戏显卡。如今,Nvidia和AMD的顶级游戏GPU仍在使用价格更低的GDDR6技术。
然而,AMD的初始预测在某种程度上是正确的:内存带宽的扩展对于GPU来说确实是一个问题,尤其是对于数据中心的GPU而言。对于消费级游戏GPU,Nvidia和AMD已经转向使用大容量缓存来存储帧缓冲区,使它们能够使用带宽较低的GDDR内存。
正如我们之前详细介绍的那样,推理和训练工作负载对内存的需求很高。随着AI模型中参数数量的指数增长,仅仅是权重的模型大小就已经达到了TB级别。因此,AI加速器的性能受到存储和检索训练和推理数据的能力的限制,这通常被称为内存壁。
为了解决这个问题,领先的数据中心GPU采用了与高带宽内存(HBM)进行共封装的方式。Nvidia在2016年推出了他们的首款HBM GPU,即P100。HBM通过在传统DDR内存和芯片上缓存之间找到了一个折衷方案,通过牺牲容量来提高带宽。通过大幅增加引脚数,每个HBM堆栈可以实现1024位宽的内存总线,这是DDR5每个DIMM的64位宽度的18倍。与此同时,通过大幅缩短距离,HBM的功耗得到了控制,每位传输的能量消耗显著降低(以皮焦每比特为单位)。相比于GDDR和DDR的厘米级长度,HBM的传输路径只有毫米级长短。
今天,许多面向高性能计算的芯片公司正在享受AMD努力的成果。讽刺的是,AMD的竞争对手Nvidia可能是最大的受益者,成为HBM的最大用户。
03.HBM市场:SK Hynix的主导地位
三星和美光投资迎头赶上
作为HBM的先驱,SK Hynix是技术路线图最为先进的领导者。SK Hynix于2022年6月开始批量生产HBM3,目前是唯一的HBM3供应商,市场份额超过95%, 亿配芯城 大多数H100 SKU产品都在使用。目前HBM的最大配置是8层16GB HBM3模块。SK Hynix正在生产12层24GB HBM3,数据速率为5.6 GT/s,用于AMD MI300X和Nvidia H100的升级版本。

HBM的主要挑战在于封装和堆叠内存,而这正是SK Hynix擅长的领域,他们积累了最强的工艺流程知识。在未来的文章中,我们还将详细介绍SK Hynix的两项关键封装创新,它们正在逐步推进,并将取代当前HBM工艺中的一个关键设备供应商。
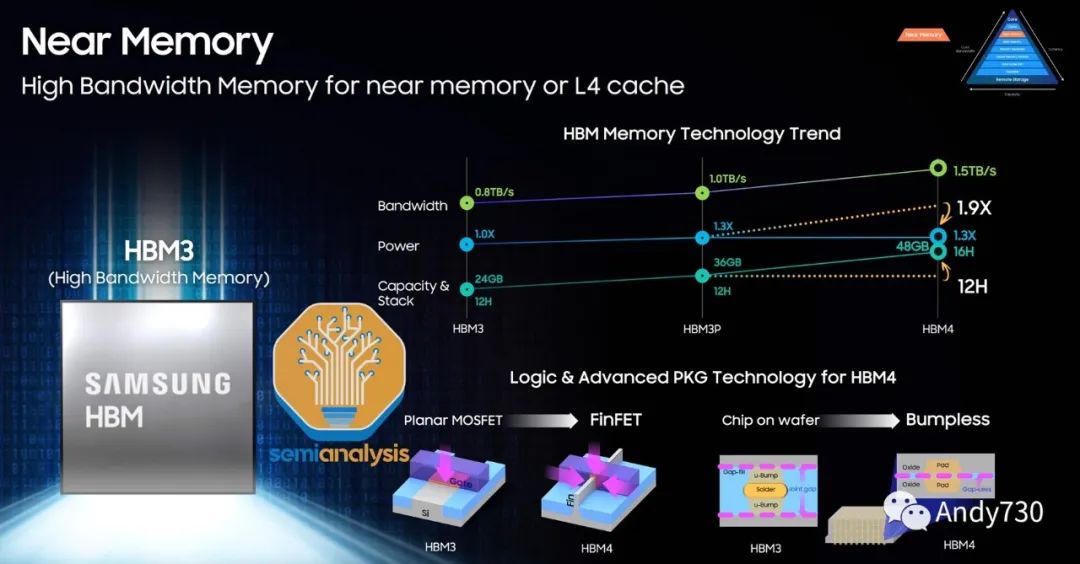
三星紧随其后,预计将于2023年下半年开始出货HBM3。我们相信它们设计用于Nvidia和AMD的GPU。目前,它们在产量上与SK Hynix相比存在巨大的差距,但它们正在大举投资以追赶市场份额。三星正在努力迎头赶上,并力争成为HBM市场份额的第一。我们听说他们正在与一些加速器公司达成有利的交易,试图获得更多份额。
他们展示了他们的12层HBM以及未来的混合键合HBM。三星HBM-4技术路线图中一个有趣的方面是,他们希望将逻辑/外围电路放在内部FinFET节点上。这显示了他们在拥有逻辑和DRAM代工厂方面的潜在优势。

美光公司目前进展最慢。美光公司在混合存储立方(Hybrid Memory Cube,HMC)技术方面进行了更大的投资。HMC是与HBM竞争的一种技术,概念非常相似,并在同一时期发展起来。然而,HMC周围的生态系统是封闭的,这使得很难在HMC周围开发知识产权。此外,HMC存在一些技术缺陷。由于HBM的采用率更高,因此HBM成为了3D堆叠DRAM的行业标准。
直到2018年,美光才开始转向HBM并进行投资。这就是为什么美光进展最慢的原因。他们仍然停留在HBM2E阶段(而SK Hynix在2020年中期开始大规模生产HBM2E),甚至无法成功制造顶级的HBM2E芯片。
在最近的财务电话会议中,美光对他们的HBM技术路线图发表了一些大胆的言论:他们相信他们将在2024年凭借HBM3E从落后者变为领先者。预计HBM3E将于2024年第三季度/第四季度开始供货,用于Nvidia的下一代GPU。
我们的HBM3规模化生产实际上是下一代HBM3,具有比当前行业中HBM3产品性能、带宽更高、功耗更低的水平。该产品将从2024年第一季度开始规模化生产,并在2024财年带来可观的收入,2025年将大幅增长,甚至超过2024年的水平。我们的目标是在HBM领域占据非常强势的份额,超过当前行业DRAM的自然供应份额。
-----美光公司首席业务官Sumit Sadana
他们声称在HBM领域的市场份额高于他们在DRAM市场的份额,这是非常大胆的说法。考虑到他们仍然在高产量上无法成功制造顶级HBM2E芯片,我们很难相信美光声称他们将在2024年初发货领先的HBM3芯片,甚至成为首个发布HBM3E芯片。在我们看来,美光似乎试图改变关于他们在人工智能领域的失败者形象,尽管与英特尔/AMD CPU服务器相比,Nvidia GPU服务器的内存容量大大降低。
根据我们的渠道检查,SK Hynix在新一代技术方面仍然保持领先地位,而三星则在大幅增加供应、提出大胆路线图并达成交易方面努力迎头赶上。
04.真正的瓶颈是CoWoS技术
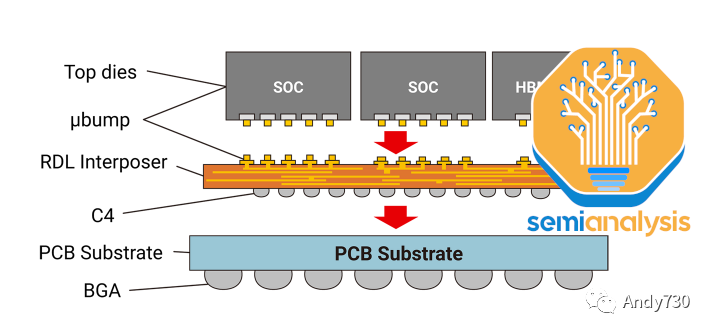
CoWoS(Chip on Wafer on Substrate,芯片在晶圆上的衬底上)是TSMC的“2.5D”封装技术,多个活性硅芯片(通常是逻辑芯片和HBM堆叠芯片)集成在一个被动硅中间层上。中间层作为顶部活性芯片的通信层。然后,中间层和活性硅芯片与包装基板连接在一起,包装基板上含有与系统PCB连接的I/O接口。
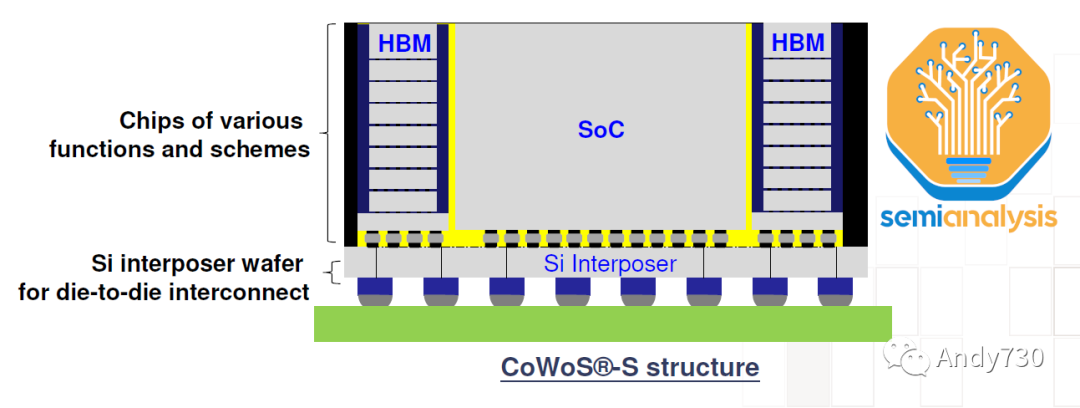
HBM和CoWoS是相辅相成的。HBM的高引脚数和短迹长要求需要2.5D先进封装技术,如CoWoS,才能实现密集、短距离的连接,这在PCB甚至包装基板上无法实现。CoWoS是主流封装技术,提供最高的互连密度和最大的封装尺寸,而成本合理。由于几乎所有HBM系统目前都采用CoWoS封装,所有先进的人工智能加速器都使用HBM,因此可以推断,几乎所有领先的数据中心GPU都由TSMC采用CoWoS封装。百度在其产品中使用了三星的高级加速器。
尽管TSMC的SoIC等3D封装技术可以直接将芯片堆叠在逻辑芯片上,但对于HBM来说,这种做法在热管理和成本方面并不合理。SoIC在互连密度方面处于不同的数量级,并更适合通过芯片堆叠扩展片上缓存,正如AMD的3D V-Cache解决方案所示。AMD的Xilinx也是多年前最早使用CoWoS技术将多个FPGA芯片集成在一起的用户。
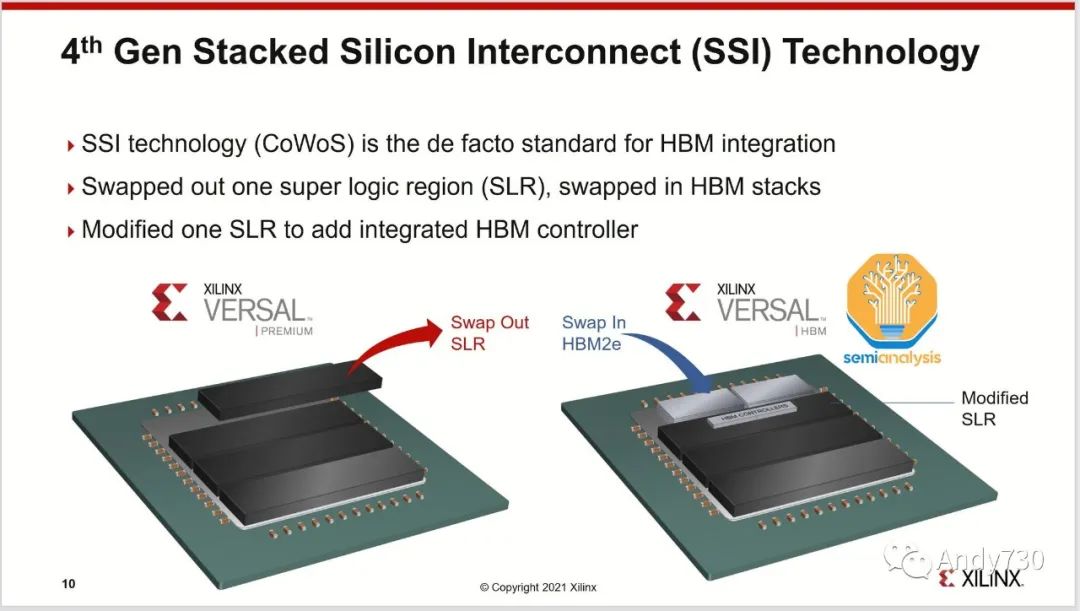
尽管还有其它一些应用程序使用了CoWoS技术,如网络(其中一些被应用于网络GPU集群,如博通的Jericho3-AI)、超级计算和FPGA,但绝大多数CoWoS的需求来自于人工智能领域。与半导体供应链的其它主要终端市场不同,这些市场的疲软意味着有足够的闲置产能来满足对GPU的巨大需求,CoWoS和HBM已经是主要面向人工智能的技术,因此2022年第一季度已经消耗了所有的闲置产能。随着GPU需求的激增,这些供应链的部分已经无法跟上,成为了GPU供应的瓶颈。
就在最近的两天,我接到了一个客户的电话,要求大幅增加后端产能,特别是CoWoS方面的产能。我们正在评估这个需求。
-----TSMC首席执行官魏哲家
TSMC一直在为更多的封装需求做准备,但可能没有预料到这股生成式人工智能需求会来得如此迅速。今年6月,TSMC宣布他们在竹南开设了先进封测 6工厂。这个工厂占地面积达14.3公顷,足够容纳每年高达100万片的3D封测产能。这不仅包括CoWoS,还包括SoIC和InFO技术。有趣的是,这个工厂的面积比TSMC其它封装工厂的总和还要大。尽管这只是净化室的面积,并远未完全配备充分的设备来提供如此多的产能,但很明显TSMC正在做好准备,预期会有更多对其先进封装解决方案的需求。
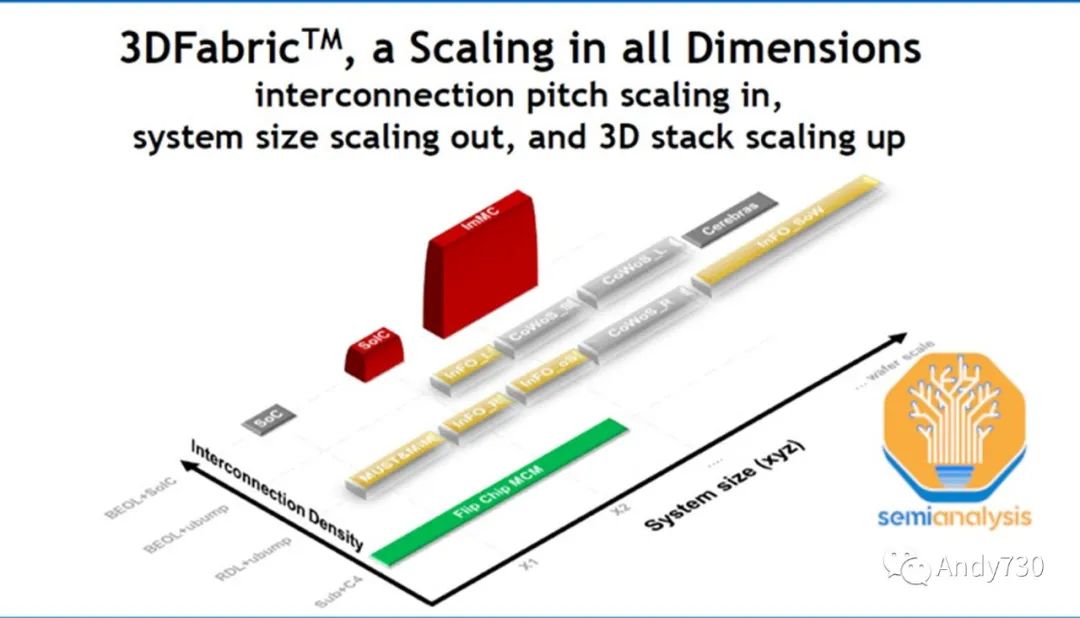
微观封装(Wafer Level Fan-Out)的产能有些闲置,这在主要用于智能手机SoC的领域比较常见,其中的一些部分可以重新用于CoWoS的某些工艺步骤。特别是在沉积、电镀、背面研磨、成型、放置和RDL(重密度线路)形成等方面存在一些重叠的工艺。我们将在后续文章中详细介绍CoWoS的工艺流程以及所有由此带来积极需求的公司。在设备供应链中会有一些有意义的变化。
英特尔、三星和外包测试组织(如ASE的FOEB)还有其它的2.5D封装技术,但CoWoS是唯一一种被大量采用的,因为TSMC是最为主导的人工智能加速器代工厂。甚至英特尔的Habana加速器也是由TSMC制造和封装。然而,一些客户正在寻求与TSMC的替代方案,下面我们将讨论这方面的内容。更多信息请参阅我们的先进封装系列。
05.CoWoS的变种
CoWoS有几个变种,但原始的CoWoS-S仍然是高产量生产的唯一配置。这是上面描述的经典配置:逻辑芯片和HBM芯片通过基于硅的中间层和TSV进行连接。中间层然后放置在有机封装基板上。

硅中间层的一项关键技术是“版图拼接”(reticle stitching)。由于光刻工具的缺陷扫描限制,芯片通常具有最大尺寸为26mm x 33mm。随着GPU芯片尺寸接近这一限制并需要适应周围的HBM芯片,中间层需要更大的尺寸,将超过这个版图限制。TSMC利用版图拼接技术来解决这个问题,允许他们对中间层进行多次版图拼接(目前最多可以达到3.5倍,与AMD的MI300相适应)。
CoWoS-R采用有机基板和重新分布层(RDL),而不是硅中间层。这是一种成本较低的变种,由于使用有机RDL而不是基于硅的中间层,牺牲了I/O密度。正如我们所详细介绍的那样,AMD的MI300最初是设计在CoWoS-R上的,但我们认为由于翘曲和热稳定性的问题,AMD不得不改用CoWoS-S。
CoWoS-L预计将于今年晚些时候推出,并使用RDL中间层,但包含用于芯片间互连的主动和/或被动硅桥,嵌入在中间层内部。这是TSMC的等效产品,类似于英特尔的EMIB封装技术。这将允许更大的封装尺寸,因为硅中间层的规模越来越难以扩展。MI300 CoWoS-S可能已接近单个硅中间层的限制。
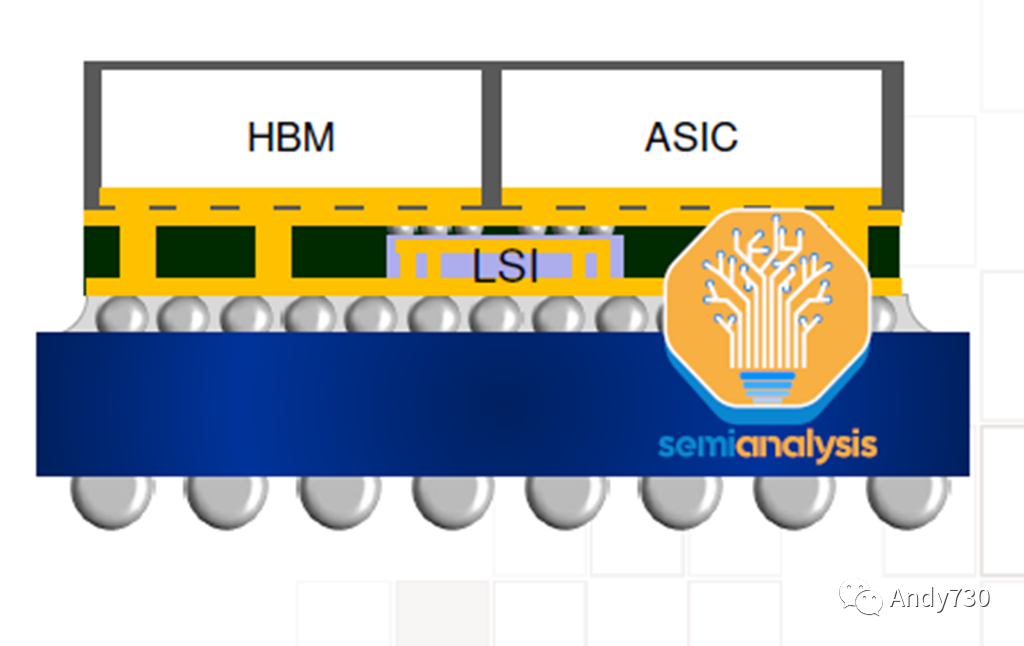
对于更大的设计来说,采用CoWoS-L将更具经济性。TSMC正在研发一个6倍版图尺寸的CoWoS-L超级载体中间层。对于CoWoS-S,他们并未提及超过4倍版图的内容。这是因为硅中间层的脆弱性。这种硅中间层只有100微米厚,当中间层在工艺流程中扩展到更大尺寸时,有可能出现剥离或开裂的风险。
- 亿配芯城接入DEEPSEEK AI 大模型,让芯片采购更灵活2025-04-25
- 电容的计算公式2024-10-31
- Taiyo Yuden品牌GMK105ABJ105KV-F贴片陶瓷电容CAP CER 1UF 35V X5R 0402的技术和方案应用介绍2024-10-15
- Taiyo Yuden品牌LMK107BJ475KAHT贴片陶瓷电容CAP CER 4.7UF 10V X5R 0603的技术和方案应用介绍2024-10-06
- Taiyo Yuden品牌LMK105BBJ475MVLF贴片陶瓷电容CAP CER 4.7UF 10V X5R 0402的技术和方案应用介绍2024-10-04
- Taiyo Yuden品牌UMK212BJ105KG-T贴片陶瓷电容CAP CER 1UF 50V X5R 0805的技术和方案应用介绍2024-09-28